How to I learnt Chinese.
Todo: this is a post-mortem of learning Chinese as a foreign language, for those who would like to try it themselves, to assess time and effort needed.
1. TODO Body
1.1. TODO References
- https://github.com/cschiller/zhongwen/ :: firefox extension dictionary
- panlatin (sound hints) :: firefox extension
- Pleco
- ChinesePOD
- Mao’s Little Red Book
- The Little Schemer
- Zhihu
- Private offline teacher
- Word plotting from pleco backups
- Chinese Word Separator
- fcitx5
- mdbg
- cedict, cc-cedict
- opencc
- Anki
- ctext.org
- Book of Change
- Emacs’ “pinyin with tone marks” input method.
1.2. TODO Text
1.3. Counting words I have learnt overtime
1.3.1. Counting words
#!/bin/bash # -*- mode:sh; -*- # Time-stamp: <2024-12-12 19:32:34 lockywolf> #+title: Print word usage from time, learning Chinese. #+author: #+date: #+created: <2024-05-09 Thu 13:19:26> #+refiled: #+language: bash #+category: #+filetags: #+creator: Emacs-30.0.50/org-mode-9.7-pre if [[ $1 == "" ]] ; then printf "usage: %s <dir>" "$0" fi { echo date words-learnt for f in "$1"/*.pqb ; do # echo "$f" REG='flashbackup-([[:digit:]]{10})\.pqb' if [[ "$f" =~ $REG ]] ; then # echo matches "${BASH_REMATCH[1]}" cdate="${BASH_REMATCH[1]}" ndate=$(stat --format='%y' "$f" | cut -f 1 -d ' ') #ndate=$(date --date="$ndate" +%s) else echo "not matches!" exit 1 fi nwords=$(sqlite3 "$f" 'select count(*) from pleco_flash_cards;') printf "%s %s\n" "$ndate" "$nwords" done } > print-word-usages.csv echo finished successfully
1.3.2. Generating a plot
1.3.3. Result
(This plot is outdated, and not re-generated regularly.)
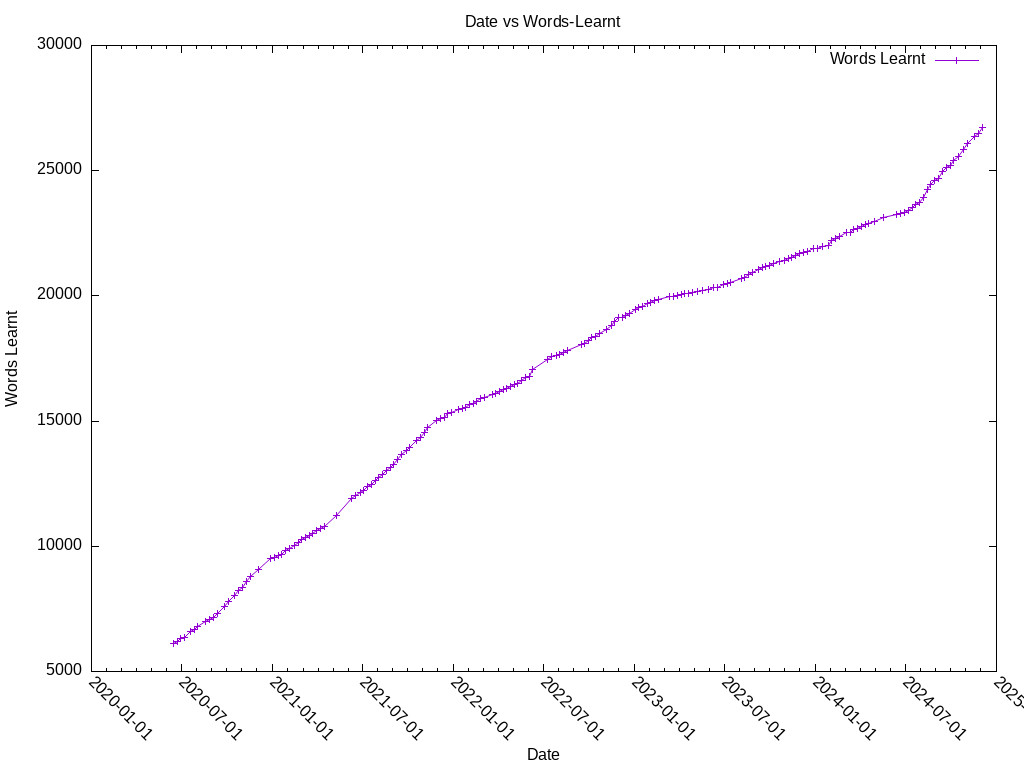
1.4. Generating a list of hard characters
I used this list for the Chinese “alphabet” https://www.hanyuguoxue.com/zidian/guifanhanzi-sn-3 , because full UNICODE is too huge. It has four groups: easy characters, middle characters, hard characters, and the rest, seldom used characters.
This script has a few nice features:
- It is still pure UNIX: bash, sed, grep, and awk, even though it does “statistical data analysis”.
- Sequential string character processing in bash is horrible (unicode BAD, BAD!), but there is a nice trick around it.
- OpenCC is a very nice tool for simplified<->traditional conversion, and this is the first time in my life I actually used co-processes in a script (albeit not in BASH).
grep -P '[\p{Han}]'is really useful.
#!/bin/bash # -*- mode:sh; -*- # Time-stamp: <2025-07-07 09:05:01 lockywolf> #+title: Make word statistics in bash. #+author: #+date: #+created: <2025-07-05 Sat 21:44:56> #+refiled: #+language: bash #+category: #+tags: #+creator: Emacs-31.0.50/org-mode-9.7-pre set -x #echo "你好嗎 新年好。全型句號" | sed -e 's/\(.\)/\1\n/g' for i in 1 2 3; do time sed -e 's/\(.\)/\1\n/g' level-$i-source.txt | grep -P '[\p{Han}]' | sort\ | uniq > level-$i-processed.txt done filename=$( cd ~/Syncthing_2021/Oneplus-5t-sdcard/2020-06-15-Pleco_backups readlink -f $(find . -iname 'flashbackup-*.pqb' | sort -r | head -n1)) echo "$filename" time sqlite3 -cmd 'select * from pleco_flash_cards ; ' "$filename" </dev/null \ | sed -e 's/\(.\)/\1\n/g' | grep -P '[\p{Han}]' | sort | uniq > my-characters.txt # | awk --field-separator='' '{ for (i=1; i<NF ; i++) ;}' if [[ ! -d ./sources ]] ; then echo "you must mkdir ./sources and copy your source files there" exit 2 fi time find -L . -type f -iname '*html' -exec cat {} + \ | awk --field-separator='' 'BEGIN{distribution[a]=1} { for (i=1; i<NF ; i++) if( $i in distribution ) { distribution[$i]++ } else {distribution[$i]=1} ;} END{ for (char in distribution ) { print distribution[char] " : " char } ; }' \ | grep -P '[\p{Han}]' | sort -V -r \ | awk 'BEGIN{while(( getline tmp < "my-characters.txt") > 0) {mine[tmp]=1 ; } ; while(( getline tmp < "level-1-processed.txt") > 0) {level1[tmp]=1 ; } ; while(( getline tmp < "level-2-processed.txt") > 0) {level2[tmp]=1 ; } ; while(( getline tmp < "level-3-processed.txt") > 0) {level3[tmp]=1 ; } ; } {printf( "%4d" " : " "%6d : %s" " : " , NR, $1, $3); if ($3 in mine) {printf(" seen") ; } else {printf("unseen")}; printf(" : "); if ($3 in level1) {printf("1"); } else if ($3 in level2) {printf("2") } else if ($3 in level3) {printf("3");} else {printf("0");} print $3 |& "opencc -c /usr/share/opencc/t2s.json" ; "opencc -c /usr/share/opencc/t2s.json" |& getline tmp ; printf(" : " tmp ) print ""; }' > sorted.txt